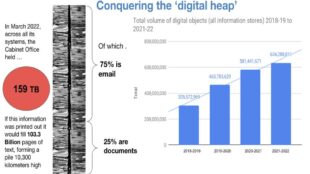
The ‘Digital Heap’
This phrase was first coined by Sir Alex Allan in his 2015 Review of Government Digital Records in which he noted that the transition from paper-based working to email and electronic documents undermined the rigour of information management across much of government.
The Government acknowledged, in its 2017 response, Better Information for Better Government, that there had been a collective and systemic information management failure. Assumptions about how busy human beings would interact with technology had been misplaced, and attempts to create digital analogues of paper driven processes had ultimately failed. This failure was not unique to the UK or to the government, but a consequence of how disruptive technology has often outpaced established administrative or legal requirements.
The ‘digital heap’ describes collections of unorganised, unstructured digital documents and information stored outside of systems of control, which leads to an increasing liability, compliance risks and mounting costs. Allan discovered that all government departments have a digital heap, that this was growing in an uncontrolled way and was ultimately leading to a failure to comply with transparency obligations and laws about the publication of historic records. Many departments have since taken steps to bring their ‘heap’ under control.
The Digital Paradigm
Unlike paper, digital information poses a unique and difficult set of challenges for records managers:
- Volumes of digital files are around one thousand times greater than for paper files;
- File plans create a complex distribution of information, and can introduce confusion, but also add a new feature that was not present in the paper world: context, how the records were organised/managed;
- Diversity of format means that ‘the record’ is not one type of information, and reconstruction of the audit trail of events may require connecting records from several different formats or applications;
- Metadata needs care and preservation, and the fact that we can’t achieve this has often been a historic technical failure, and remains a challenge for digital interoperability.
This forces us to face some challenging questions about the nature of digital records: First, where are they and what are they?
Second, how do we locate the ones we care about in a corpus so large and complex that it cannot be easily understood by humans without the injection of huge resources over such a long period that makes human review laughably impractical?
Culture
A major part of tackling the digital heap is to change the culture that allowed it to be created in the first place. Heaps are created through a lack of standards and rules, poor enforcement and leadership focus. Since 2015, Cabinet Office has introduced new policies for the digital age, rigorously enforced its Information Management Standards Framework, carrying out an audit of how well each team is complying every quarter. The results of these audits are reported to senior leaders who support active interventions by the Digital KIM Team. The National Archives carried out an assessment of Cabinet Office in 2018 and awarded a ‘Green’ rating, another first. Cabinet Office have successfully maintained high standards since, even through the disruption of the Covid pandemic.
Innovation and Automation
In one of our ‘heaps’ there were over 11 million files all of which needed to be reviewed before they could either be retained as a historic record or destroyed. We estimated that it would take one person 59 years to read them all, and if we attempted to employ 59 people to complete the task in one year, the paybill would exceed £2million.
Even if we kept them all, we would need to repeat the review task before transferring the records to The National Archives in order to avoid accidentally publishing sensitive material, so the cost would be inescapable and significant. What we needed was a solution that allowed us to understand what the records in our heap contained, their value, and to facilitate rapid decision making about their disposal using only our existing people resources.
We achieved this through development of:
- A disposal methodology based on high level analysis and risk based decision making; and
- An algorithm for decision making that is capable of being automated.
The disposal methodology aims to rapidly de-bulk a corpus of digital information through identifying and removing redundant, outdated and trivial (‘ROT’) information through a series of ‘filtration’ stages:
- Classification analysis: we review the top level file plan, investigating obvious sections of it that may be ROT and removing them if this is confirmed;
- We then remove all unwanted file formats in which we do not believe valuable information is stored; this will include empty and obsolete formats, and we apply our tacit knowledge of how the department has used these formats in the past;
- We then move to aggressive reduction through applying what we have called The Lexicon, to the metadata, file name, file path, and the file content. The Lexicon is a model for using coding language in elastic search to identify the content of documents that may be either ROT or records of value. Elastic search is a powerful indexing language and integrates with the technology we are using.
- We also apply weighting to this based on a matrix of file format and content to resolve ‘grey areas’.
The Lexicon
We developed a theory based on analysis of historic files, that documents of historical value contain particular patterns of language: key words and phrases that tend to appear more frequently than in ROT information.
These words or phrases, along with their frequency are predictable and therefore software could be programmed to locate them in a large corpus of documents. After an initial pilot, then a set of tests and comparative analyses, we were able to demonstrate that this theory is valid, and produce an automated system for analysing large volumes of digital records for disposal. At the heart of the system is our Lexicon. This is the list of words and phrases that determine value. We are very aware that language in the workplace evolves constantly, and so we will need to keep our Lexicon up to date through regular review.
Preservation and digital continuity
Having removed the ROT, a further important step in taking control of digital information is to ensure it is preserved appropriately and that the organisation knows what it is keeping, and why.
So, after we have carried out disposal activity, records that we want to keep are preserved in specialist preservation software that provides rich metadata, search capability and assures fixity, right down to the ones and zeros. The importance of records integrity is vitally important for us because we are responsible for preservation of the records of former Prime Ministers and the Cabinet.
Our preservation system populates a digital catalogue, a database that helps us to navigate through the digital archive and locate records as required.
Where next?
Conquering the digital heap problem creates huge opportunities for the Government. Having control over a known body of information provides the means to introduce better knowledge management, further reducing cost and inefficiency. Our Lexicon forms the basic programming language required to develop true artificial intelligence solutions in future. These initiatives will form core parts of our development work in the next few years.
About the author
David Canning is the Head of Digital Knowledge & Information Management in the Cabinet Office, a post he has held since 2015. He is also a tutor in records management at the University of Dundee.
2 comments
Comment by Venus Bailey posted on
Love the impact of this piece of work!
Comment by Nayyab Naqvi posted on
Thank you for sharing your thoughts :). I always refer to it to explain the Digital heap challenge